一个只能达到 cublas 80% 性能的 FP32 trsm 实现
本文阅读的前提是假设你对 GPU 的体系结构有一般的认知,如果没有,推荐 Bilibili 相关的入门视频,可以看
稍微看一下,对 warp divergence 和 register spilling 有个初步的理解就可以了。
算法上很好理解:
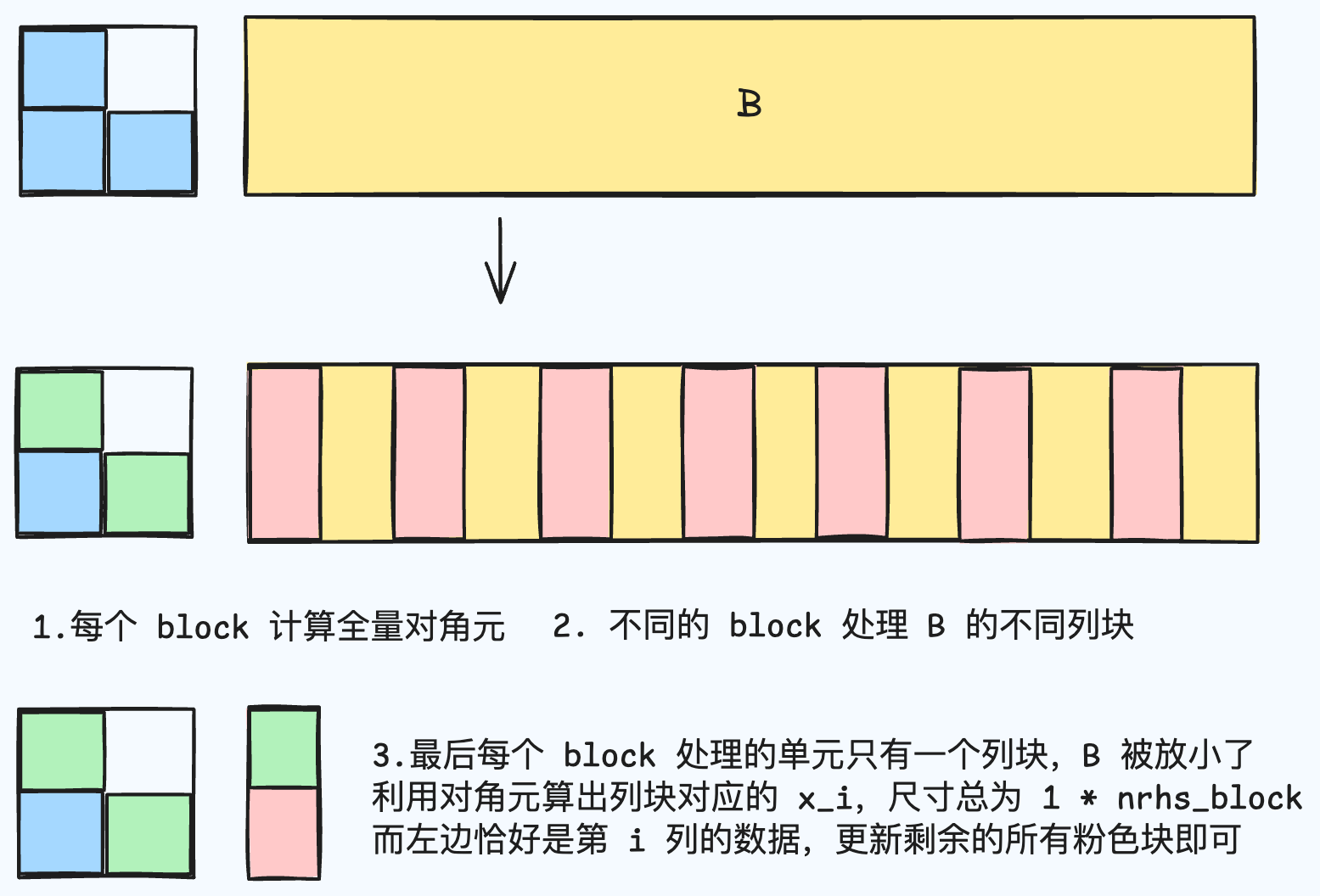
大概如上图所示。
代码的 gist 地址为 https://gist.github.com/Ruinique/4e570ebff19cc7b510bafbeb638c9892
一些的优化技巧可以参考优化 GEMM 的文章,这里推荐的是 有了琦琦的棍子的 GEMM 优化,这里用到的优化是 tiling + vectorized load/store + prefetching。
有空的话会写一个逐行解读,阅读和参考的资料可以参考上文。