cusolverDx 3.0 文档中文翻译
The cuSolver Device Extensions (cuSolverDx) 库可以让我们把一些 cuSolver 和 cuSparse 库中的矩阵分解,线性求解器和特征值求解器在 CUDA 的 Kernel 中执行。 我们可以通过融合这些操作和其他计算,从而拿到一个更低的时延,提高我们应用整体的性能表现。
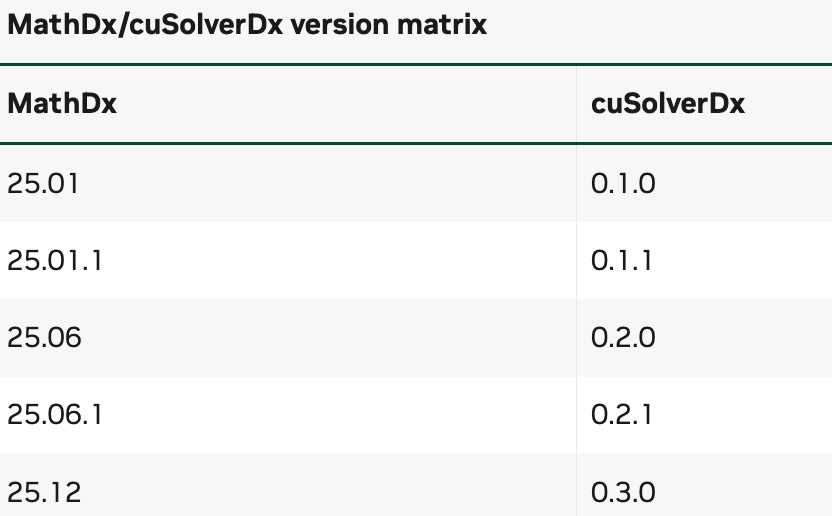
cuSolverDx 是 MathDx 的一部分,MathDx 还包含了 cuBLASDx cuFFTDx cuRANDDx 和 nvCOMPDx ,他们分别是为了 BLAS、FFT、随机数生成和数据的压缩和解压。这些扩展设计出来就是为了一起工作的,所以如果我们要需要在一个单体项目中用不同的扩展,必须保证他们的 MathDx 的版本是一致的。
现在 cuSolverDx 提供了下面的功能
- 可以嵌入到 Kernel 中的高性能的批量 Cholesky、LU 和 QR 分解,三对角矩阵、三角矩阵和全矩阵的线性系统求解,最小二乘求解,特征值求解和奇异值求解函数
- 可以自定义配置不同的矩阵规模,精度,类型,填充类型,存储布局和目标架构,从而进一步组合这些函数来适配不同的应用场景。
- 通过融合这些函数和其他 Kernel 的操作,从而减少访存。
下面是一个我们需要用到的软件的前置要求的清单:
- 如果要用
cuda12的package,需要 CUDA Toolkit 12.6+,如果要用cuda13的package,需要 CUDA Toolkit 13.0+ - 支持的 CUDA 编译器,支持 C++17
- 支持的主机端编译器,支持 C++17
- (可选)3.18 及以上的 CMake 依赖:
- commonDx
- CUTLASS
支持的系统架构
Section titled “支持的系统架构”- x86_64
- AArch64
cuSolverDx 作为 MathDx 包的一部分进行分发。要下载包含 cuSolverDx 的 MathDx 包的最新版本,请访问 https://developer.nvidia.com/cusolverdx-downloads 网站。
在项目中使用 cuSolverDx
Section titled “在项目中使用 cuSolverDx”要使用 cuSolverDx 库,我们用户需要 include 包含 cusolverdx.hpp 的目录(该头文件依赖于 commonDx 和 CUTLASS,它们随 MathDx 包一起提供),以及与 cuSolverDx LTO 库链接(Link Time Optimization)。cuSolverDx 以两种形式提供其库:静态库 libcusolverdx.a 和 fatbin 库 libcusolverdx.fatbin。
libcusolverdx.fatbin 库仅包含设备代码,因此与主机平台无关。所以它可以在 AARCH64 平台上安全使用,而 libcusolverdx.a 仅适用于 x86_64 Linux 构建。
// When using libcusolverdx.anvcc -dlto -std=c++17 -arch sm_XY (...) -I<mathdx_include_dir> <your_source_file>.cu -o <your_binary> -lcusolverdx
// When using libcusolverdx.fatbinnvcc -dlto -std=c++17 -arch sm_XY (...) -I<mathdx_include_dir> <your_source_file>.cu -o <your_binary> libcusolverdx.fatbin-dlto 选项在链接时指示链接器从库对象中获取 LTO IR,并对生成的 IR 进行优化以生成代码。
使用 NVRTC 和 nvJitLink 进行运行时内核编译和链接时,可以使用libcusolverdx.fatbin 或 libcusolverdx.a 的 fatbin 文件。除了 x86_64 Linux 以外的平台,必须使用fatbin。
当您将 MathDx YY.MM 包的 tarball 解压到 <your_directory> 时,cusolverdx.hpp 文件将位于以下位置:
<your_directory>/nvidia/mathdx/yy.mm/include/
库文件 libcusolverdx.a 和 libcusolverdx.fatbin 将位于:
<your_directory>/nvidia/mathdx/yy.mm/lib/
commonDx 头文件将位于以下位置:
<your_directory>/nvidia/mathdx/yy.mm/include/
详细要求列在要求部分。
在 CMake 项目中使用 cuSolverDx
Section titled “在 CMake 项目中使用 cuSolverDx”MathDx 软件包提供了简化在其他 CMake 项目中使用 cuSolverDx 的配置文件,我们使用 find_package 找到 mathdx 后,用户必须将 mathdx::cusolverdx 链接到他们的目标。这确保设备链接到 libcusolverdx.a,并传播 cusolverdx_INCLUDE_DIRS、commonDx和 CUTLASS 的依赖关系和 C++17 标准到用户的 target。
当 CMake 检测到 NVCC CUDA 编译器 12.8+ 时,MathDx 的mathdx::cusolverdx_fatbin 就可以用了。它可以用来代替 mathdx::cusolverdx。因为只包含 device 侧的代码,所以这个可以用在不同的平台上。
要在 CMake 中为某个 target 启用 LTO,请将 INTERPROCEDURAL_OPTIMIZATION 设置为 true,并将 CUDA_SEPARABLE_COMPILATION 设置为 true 以允许设备代码的单独编译。我们用 set_target_properties 设置目标的这个变量。不管是 fatbin 还是 mathdx::cusolverdx,这个都是必须要干的。
# find cuSolverDxfind_package(mathdx REQUIRED COMPONENTS cusolverdx CONFIG)# enable LTO in your targetset_target_properties(YourProgram PROPERTIES CUDA_SEPARABLE_COMPILATION ON INTERPROCEDURAL_OPTIMIZATION ON)# link against mathdx::cusolverdxtarget_link_libraries(YourProgram mathdx::cusolverdx)# or against mathdx::cusolverdx_fatbintarget_link_libraries(YourProgram mathdx::cusolverdx_fatbin)我们可以在 CMakeLists.txt 里配置
find_package(mathdx REQUIRED COMPONENTS cusolverdx CONFIG PATHS "<your_directory>/nvidia/mathdx/yy.mm/")当然,也可以设置 mathdx_ROOT 通过在使用 cmake 的时候配置
cmake -Dmathdx_ROOT="<your_directory>/nvidia/mathdx/yy.mm/" (...)mathdx::cusolverdx 静态库产物,mathdx::cusolverdx_fatbin 是 fatbin 产物(只在 12.8 以上的版本上可用)
mathdx_cusolverdx_FOUND, cusolverdx_FOUND
如果找到了,这个值为 true
cusolverdx_INCLUDE_DIRS
include 的路径
mathdx_INCLUDE_DIRS
MathDx include 路径
cusolverdx_LIBRARIES
cuSolverDx 库
cusolverdx_FATBIN
libcusolverdx.fatbin 库
cusolverdx_LIBRARY_DIRS
cuSolverDx 库的路径
mathdx_VERSION
MathDx 的版本号
cusolverdx_VERSION
cusolverDx 的版本号
cuSolverDx 库提供了一套全面的稠密矩阵操作,可以直接在 CUDA kernel 函数中执行。这些操作设计得高效且可以方便的自定义,能够在各种计算场景中实现最佳性能。
- 矩阵分解
- Cholesky 分解(POTRF)
- 带和不带部分选主元的 LU 分解(GETRF)
- QR 和 LQ 分解(GEQRF,GELQF)
- 线性系统求解
- 三角系统求解(TRSM)
- 三对角系统求解(GTSV_NO_PIVOT)
- 使用 Cholesky 分解后再求解线性系统(POTRS)
- 使用 LU 因子求解线性系统(GETRS)
- 最小二乘问题求解(GELS)
- 矩阵操作
- 使用 QR 和 LQ 分解中的 Q 进行矩阵乘法(UNMQR,UNMLQ)
- 从 QR 和 LQ 分解中生成 Q(UNGQR,UNGLQ)
- 特征值求解
- 对称三对角矩阵的特征值和特征向量求解(HTEV)
- 对称矩阵的特征值和特征向量求解(HEEV)
- 奇异值分解
- 对一般矩阵的奇异值分解(GESVD)
- 对带对角线矩阵的奇异值分解(BDSVD)
- 性能优化
- 支持实数和复数数据类型
- 可配置的矩阵存储布局(列主序和行主序)
- 针对特定架构的优化
- 支持批量操作,提升吞吐量
- 集成能力
- 与其他 CUDA 操作的无缝集成
- 支持 Shared Memory 的使用
- 可自定义 block size 和每个 block 做多少 batch
如果要拿到进一步的信息,可以直接从下面的链接跳转过去:
- Linear Solve
- Least Squares
- Orthogonal Factors
- Symmetric Eigenvalues
- Singular Value Decomposition (SVD)
- BLAS
感觉貌似每个 block 执行的都是独立的,似乎只能做一个 batched 的启动。所以暂停先停工。